##hash
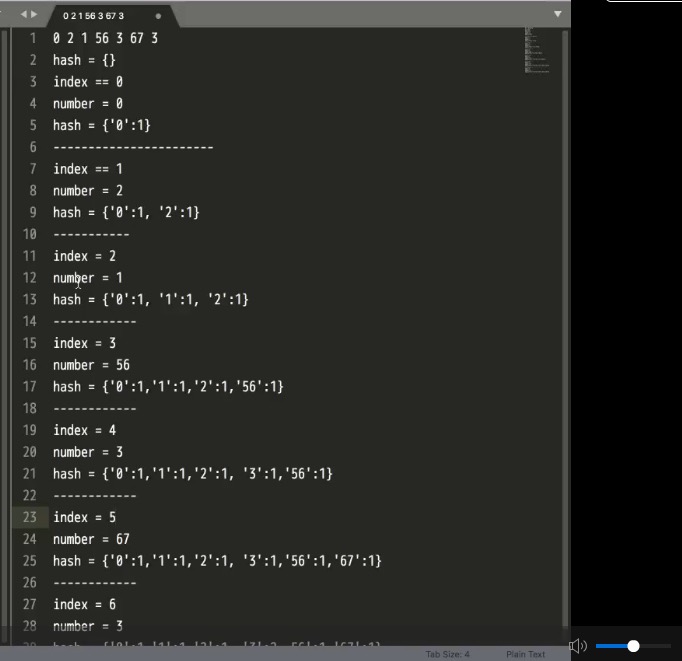
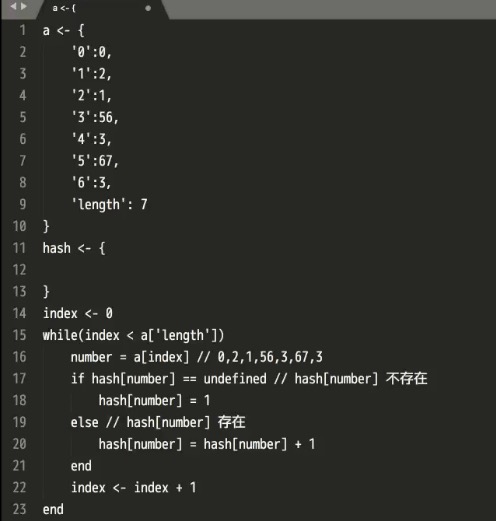
- 数组的长度不根据key决定,而是数组中最大的数字加1(要算上0)在大部分语言是这样的,有部分语言不从0开始就不加1。
- 便利我们的哈希
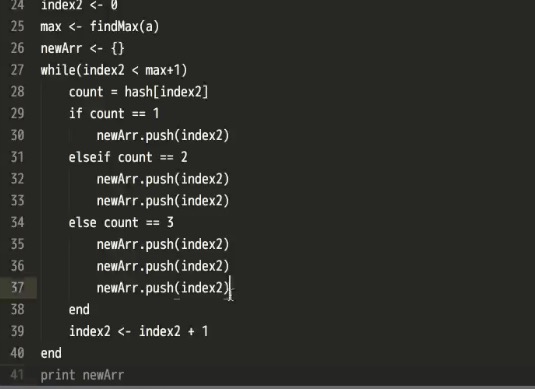
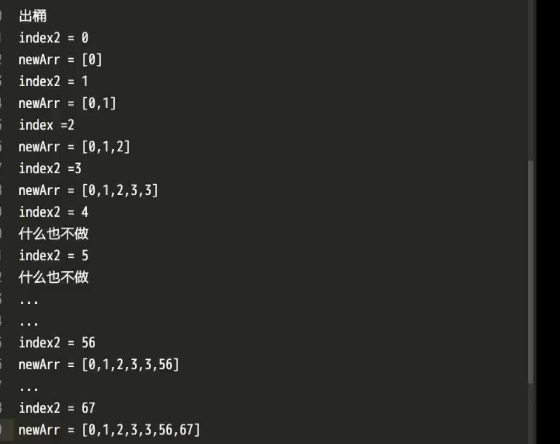
- 继续优化哈希
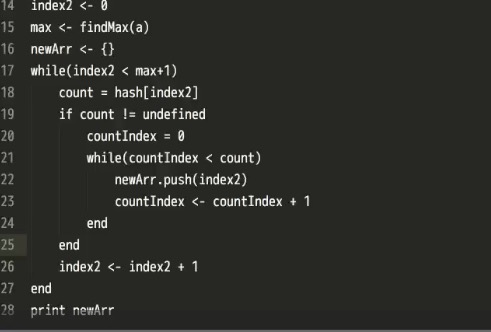
- If count != underfined代表如果count不等于underfined时,就运行下面的循环。
哈希的优点:快,缺点:无法比较小数和负数
##桶排序:
1.
- 可以再对每个桶做快排,比起上面的计数排序,节约了桶,但是要做二次排序。(节约桶,浪费了时间,cpu)
- 排序要么浪费空间要么浪费时间。
##基数排序:
- 让每个数字从个位数从小到大,再从十位数从小到大,以此类推,直到排序结束。
桶的个数固定,根据几进制就有几个桶。
##队列:
- 先进先出,以买票为例。数组实现很方便。(基数排序可以把桶看成队列,先进先出)(入push,出shift)
##栈:
- 先进后出,如盗梦空间,先进入第一层梦,再进入第二层梦,再进入第三层梦。但是出来要从第三层梦出来,再第二层,第一层。(入push,出pop)
##链表:
- 如果数组要删一个数字,首先要把这个数字的内容删掉,再把后面的数字的内容往前提一位,然后删除最后一位,然后更改length
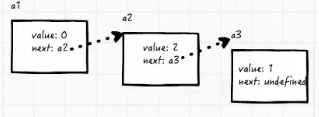
- 这就是链表,如果要删除a2,就让a1指向a3即可,这样a2就被忽略掉了。
- 第一个哈希叫做head,有表头就能找到接下来所有的。
##树
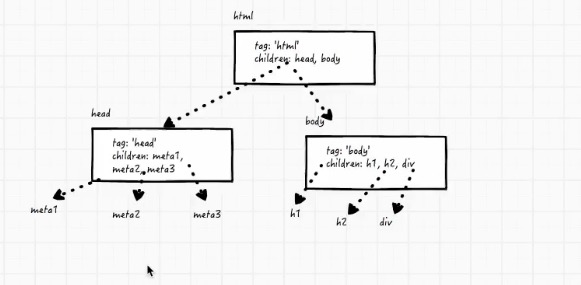
###哈希满足这个结构,就是树。
1.用数组来存树
2.堆排序可以理解是:先儿子之间比,在让大儿子和爸爸比,比爸爸大的话就互换位置。并且每个被换成儿子的节点还要和下面的节点对比。这样一个一个从大到小排序。必须维持是完全二叉树,所以会把最大的那个数与最后的数交换位置,并且不会继续参与堆排序了,也就保证维持了完全二叉树。最开始的一次复杂,后来的都简单很多了。
